[CSAPP] malloc lab(1) 동적 메모리 할당기를 탐구해보자.
![["malloc 썸네일 이미지"]](/assets/img/posts/mallocLab/mallocThumb.jpg)
“malloc은 단순히 메모리를 ‘할당’해주는 함수일 뿐일까?
CSAPP에서 제시한 malloc 프로젝트를 따라 직접 동적 메모리 할당기의 구조를 시뮬레이션해보며 malloc을 조금 더 깊게 이해 해볼 것이다.
이제부터 malloc, free, realloc기능을 구현하면서 동적 메모리 할당기가 어떻게 동작하는 지 알아보자.
먼저 동적 메모리 할당기가 수행하는 동작들에 대해서 알아보자.
malloc, free, realloc
위의 세가지 동작들은 동적 메모리 할당기의 핵심적인 동작이며 동시에 우리가 지금부터 구현해야 할 함수들이다.
아래에 각각의 함수들이 수행하는 동작을 간단하게 적어 놓았다. 자세한 내용은 실제 함수를 구현할 때 알아보자.
malloc
malloc은 메모리를 할당해준다.
요청한 크기의 블록을 찾아서 반환한다. 없으면 새로운 heap공간을 확장한다.
free
free는 할당된 메모리를 해제하고 재사용할 수 있는 공간으로 만들어준다.
realloc
realloc은 메모리를 재할당해준다.
기존 블록을 새 크기로 변경한다. 필요하면 새로운 블록으로 복사한다.
다음으로 동적 메모리 할당기가 어떤 형태로 메모리를 저장하고 관리하는지 알아야 한다.
동적 메모리 할당기의 메모리 관리 방식
동적 메모리 할당기는 가상메모리의 heap영역에서 블록단위로 메모리를 관리한다.
csapp 실습기준으로 우리는 32비트 기준 더블워드 정렬을 맞춰야 한다.
8바이트 정렬
이를 위해 우리는 메모리를 할당 시 공간을 8의 배수에 맞춰 메모리를 할당하고 남는 부분에 패딩을 줘야 한다.
이유는 간단하다. 32비트 시스템에서도 8바이트의 크기를 가지는 타입인 double과 long long 때문이다.
여기서 의문을 가지는 사람들이 많을 것이다. 32비트 운영체제에서 레지스터는 어차피 한 번에 4바이트 만큼의 데이터 밖에 읽지 못 하는 데 왜 굳이 8바이트 정렬을 맞춰야 하는지에 대해서다. 나 또한 이러한 의문을 가졌었다. 물론 하나의 레지스터는 double과 long long타입을 한 번에 읽지 못한다.
하지만 CPU의 명령어 수준에서 메모리 시스템(버스, 캐시, 메모리 컨트롤러)은 이 들이 8바이트의 데이터로 들어 올 것이라고 기대하고 있다. 따라서 double을 읽을 때 CPU는 내부적으로 레지스터 2개를 사용하거나, 메모리 시스템에서 연속된 두 번의 접근을 수행한다. 이를 다른 수준에서 임의로 나눠서 명령을 보내면 시스템은 느리게 읽거나(x86은 어떻게든 읽어냄) 버스 에러(ARM, MIPS 등 에서)를 내게 된다.
경계 태그
앞뒤 블록과의 병합을 쉽게 하기 위하여 블록 양쪽에 기록해 놓은 header/footer를 칭한다.

위 그림은 하나의 단위의 블록의 구성요소이다.
header
블록의 맨 앞에 위치한다. footer와 달리 항상 존재한다.
저장내용
- 블록의 전체 크기
- 할당 여부(1 비트) -> 할당됨(1)/비어있음(0)
보통 4바이트 또는 8바이트의 크기를 가진다. csapp에서 제시한 구현법이 32비트 시스템 기준이기에 우리는 header를 4바이트로 설정할 것이다.
우리는 더블워드(2*4bytes) 정렬을 사용하기에 블록의 크기는 항상 8의 배수를 가진다.
8을 바이너리로 변환하면 1000이다 8의 배수를 사용한다는 것은 어떠한 경우에도 바이너리 코드의 뒤 3자리는 000이 보장된다는 것이다. 하위 3비트는 항상 0이라는 것이다. 이 덕에 그 공간에 할당 유무를 저장 할 수 있다. 하위 첫번째 비트에 1(할당됨)/0(비어있음)을 명시하는 것이다. 인간의 숫자로 표현하면 이렇다.
“(8 * n + 1) == 8 * n 바이트 크기를 가진 블록으로 이루어진 할당된 공간” / “(8 * n + 0) == 8 * n 바이트 크기를 가진 블록으로 이루어진 할당되지 않은 공간”
footer
헤더와 동일한 정보가 저장된다. 양방향 병합을 쉽게하기 위해서 존재하며 보통 free블록에서 사용된다.
payload
사용자가 직접 사용하는 메모리 영역이다. malloc이 리턴하는 포인터는 payload 영역의 시작주소를 가르킨다. 우리는 더블워드 (8바이트) 정렬규칙을 따를 것이다.
다음으로 heap에서 malloc이 관리하는 전체 영역, 그러니까 블록들이 존재하는 영역을 어떻게 명시하는 지 알아보자.
프롤로그 블록과 에필로그 블록
프롤로그 블록
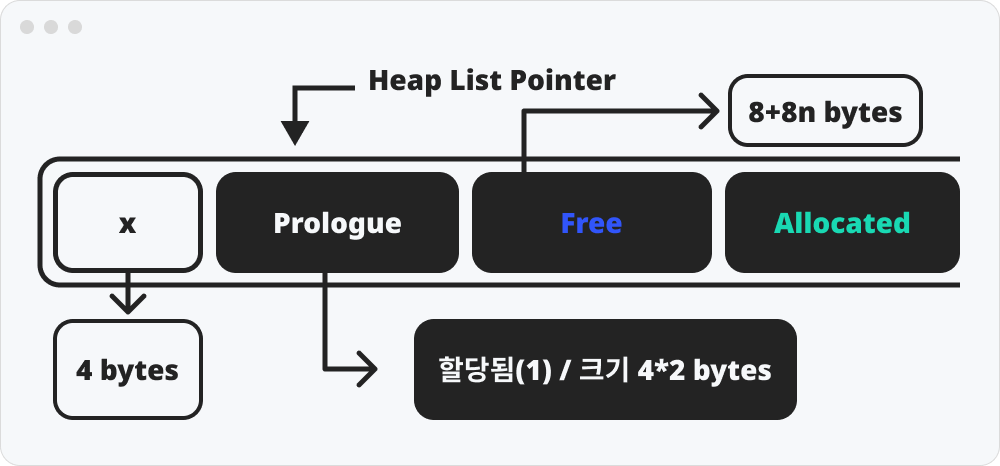
프롤로그 블록은 힙의 맨 앞에 존재하는 작은 dummy 블록이다. 탐색 및 병합 중 경계 조건을 단순하게 만들어 준다. 탐색과 병합은 free 블록을 찾아서 하는 것이기 때문에 “할당됨”으로 표시 된 프롤로그 블록은 자신의 크기만큼 탐색 포인터를 넘겨버린다.
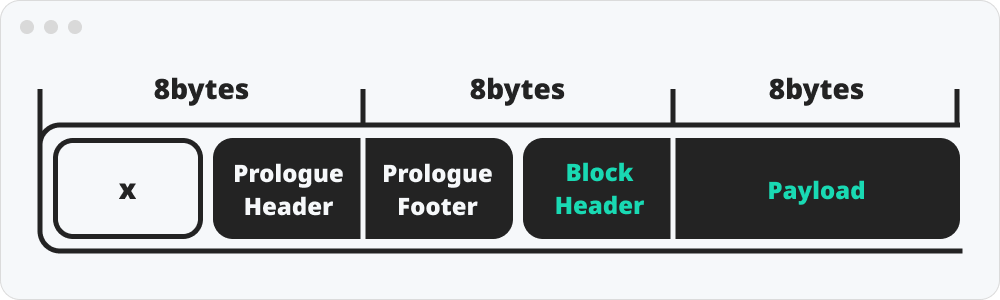
앞 4bytes의 공백의 이유는 위에서 설명한 8bytes정렬을 맞추기 위함이다. 시스템이 8바이트 씩 읽어야 하는 것이 실제 데이터가 들어가는 페이로드이기에 8바이트 정렬에 패이로드가 맞게 들어와야한다.
(free 블록이 8+8n bytes인 이유는 헤더+푸터+8바이트 정렬*n이기 때문이다)
에필로그 블록

힙 맨 마지막에 존재하는 블록이다. 이 블록은 “할당됨”으로 표시된 0바이트짜리 블록이다. 실제로는 헤더의 크기인 4바이트를 가지고 있지만 탐색종료 시점을 명시하기 위하여 앞으로 더 이상 읽을 필요가 없음을 뜻하는 0바이트의 크기로 헤더에 표시해둔다. 프롤로그와 마찬가지로 free 블록과 병합시 무시하기 위해 “할당됨”으로 표시되어 있다. 힙 확장 시 에필로그 블록은 뒤로 밀려나가게 된다.
그럼 이제부터 메모리를 할당하고 해제하는 과정에서 나타나는 문제에 대해서 알아보자.
단편화
단편화는 쉽게 말해 메모리가 낭비되는 현상을 말한다. 전체 메모리는 충분하지만 malloc의 요청에는 만족하지 못 하는 현상이다. 단편화는 내부 단편화, 외부 단편화 두 가지로 분류된다.
내부 단편화
내부 단편화는 자신의 크기보다 큰 free 블록에 메모리를 할당해서 생긴다.
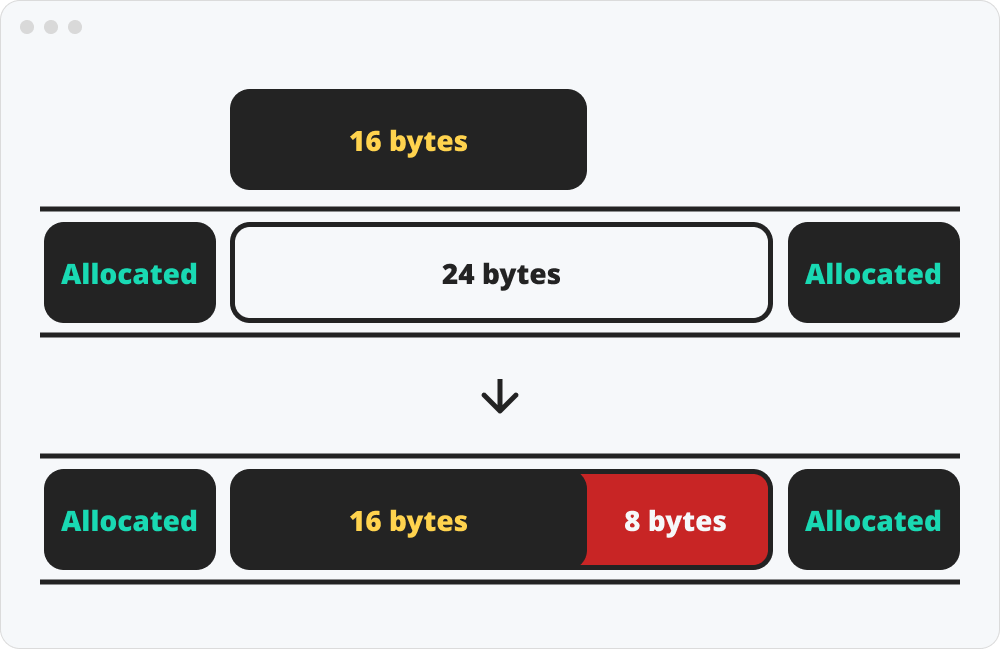
할당된 블록이 해제되어 free블록이 되었는데 이 다시 할당하는 블록이 이 보다 작을 때 생긴다. 실제로 할당하려는 공간이 딱 맞는 경우도 드물고 작으면 다음 블록으로 탐색을 이어나가니까 내부 단편화가 안 생기는 경우 보다 생기는 경우가 더 자연스럽다.
내부 단편화의 문제는 공간이 낭비된다는 것이다. 그래서 다음에 나올 외부단편화에 비해서는 조금 중요도가 낮지만 해결하지 않고 지나칠 문제도 아니다.
이를 완화해주는 예방법이 뒤에서 알아볼 “분할(split)”이다.
외부 단편화
전체 메모리 공간이 충분히 남아 있지만 메모리를 할당할 만큼의 공간을 가진 free블록이 없을 때 발생한다.
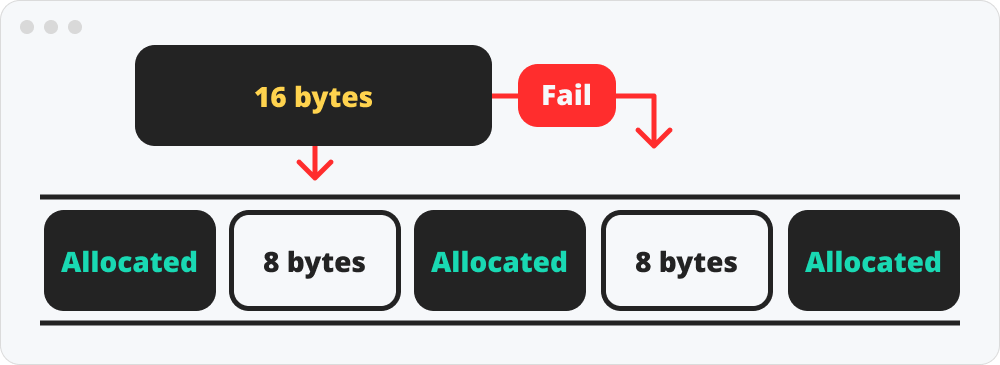
해제한 블록들을 효율적으로 재 활용하지 못해서 발생한 것이다.
이를 해결하기 위한 방법이 뒤에서 알아볼 병합(coalescing)이다.
병합이 외부 단편화의 해결 법이라 말할 수 있는 이유는 아래의 그림을 보면 이해가 된다.
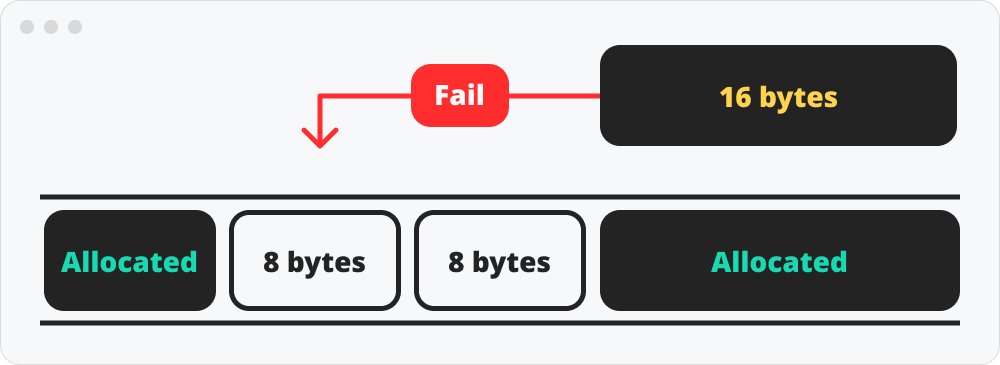
위의 상황 역시 외부 단편화로 분류되기 때문이다. 어쩌면 가장 치명적인 외부단편화이다.
계속 힙영역을 확장하면 되지 않냐고 할 수 있겠지만 힙영역을 언제까지나 확장 할 수 있는 것은 아니고 정도 이상의 힙확장을 커널에서 막을 수도 있기 때문이다. 조금의 잘못된 설계로 외부단편화는 심각히 많이 발생할 수 있기에 외부 단편화는 내부 단편화에 비해 치명적이다.
바로 이어서 단편화를 해결하는 방법을 알아보자
분할과 병합
단편화를 완전히 해결할 수는 없지만 불필요한 단편화는 최소화 할 수 있다. 그 방법이 분할과 병합이다.
분할(Splitting)
분할은 하나의 큰 free블록을 잘라서 할당하고 나머지는 남겨두는 것을 말한다.
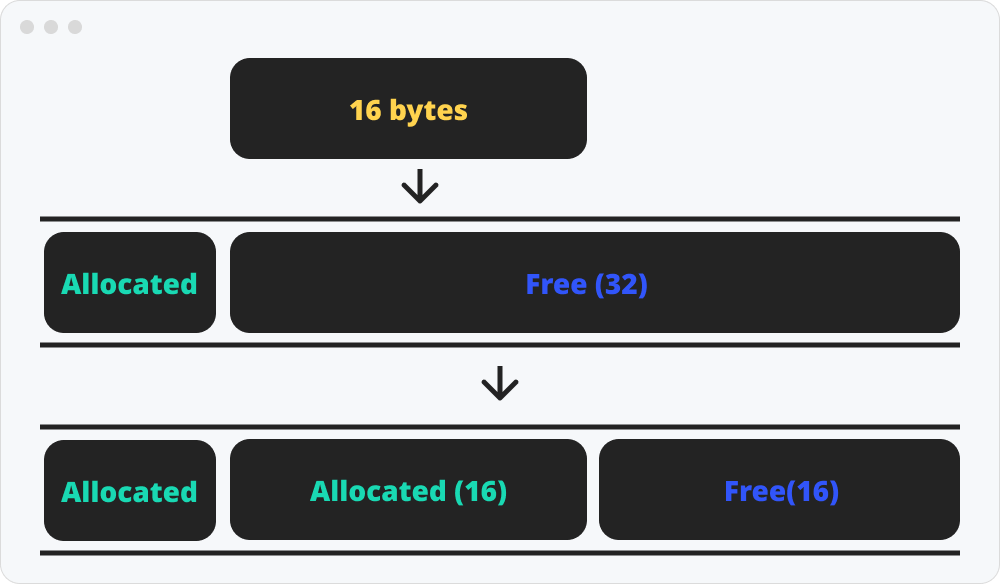
free 블록에 새로운 메모리를 할당 할 때, 할당 후 남은 크기가 최소블록크기(헤더+푸터+더블워드)보다 크다면 다른 데이터를 할당할 수있는 공간이다. 그러므로 이 공간을 분할 해서 새로운 free 블록으로 만든다.
병합(Coalescing)
병합은 메모리 해제시 인접한 free 블록과 합쳐주는 것을 말한다.
위에서 봤듯이 인접한 각기 다른 free 블록이 생기면 치명적인 외부 단편화문제가 발생한다.
이를 해결하기 위한 방법이 병합이다.
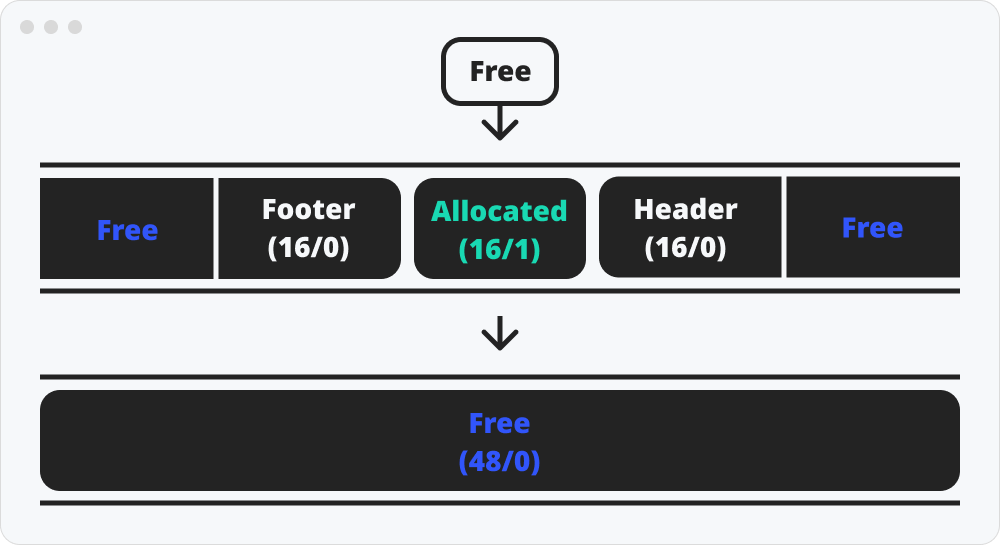
현재 블록기준 확실하게 위치가 보장되는 경계태그는 “이전 블록의 푸터”, “이후 블록의 헤더”이다. 전, 후의 경계태그를 확인하고 할당 정보가 0이면 병합을 하여 하나의 free 블록으로 만든다.
이제 free 블록을 어떻게 탐색하고 할당하는 지 알아볼 순서가 됐다.
할당전략
할당 전략은 malloc의 요청을 처리할 free 블록을 결정하는 정책이다.
| 전략 | 설명 | 장점 | 단점 | 단편화 영향 |
|---|---|---|---|---|
| First Fit | 앞에서 부터 완전탐색 중 → 처음 맞는 블록 | 탐색 시간 짧음 | 앞쪽에 조각이 많아짐 | 외부 단편화 ↑ |
| Next Fit | 이전 탐색 위치 다음 부터 완전탐색 | 일부 분산됨 | first fit 보다 느릴 가능성 있음 | 외부 단편화 ↑ |
| Best Fit | 완전 탐색 완료 후 들어갈 수 있는 가장 작은 것 | 내부 단편화 ↓ | 탐색 오래 걸림 외부 단편화 ↑ | 내부 단편화 ↓ 외부 단편화 ↑ |
| Worst Fit | 가장 큰 블록을 쪼개서 사용 | 나머지 블록을 사용할 수 있음 | 탐색 오래 걸림 | 외부 단편화 ↑ |
모르겠으면 외워라.
다음으로 free 블록들을 어떻게 관리하는 지 알아보자. 이것이 동적 메모리 할당기의 핵심이다.
free 블록 리스트를 구성하고 연결하는 전략
이 없는 것이
묵시적 가용(free) 리스트
이다.
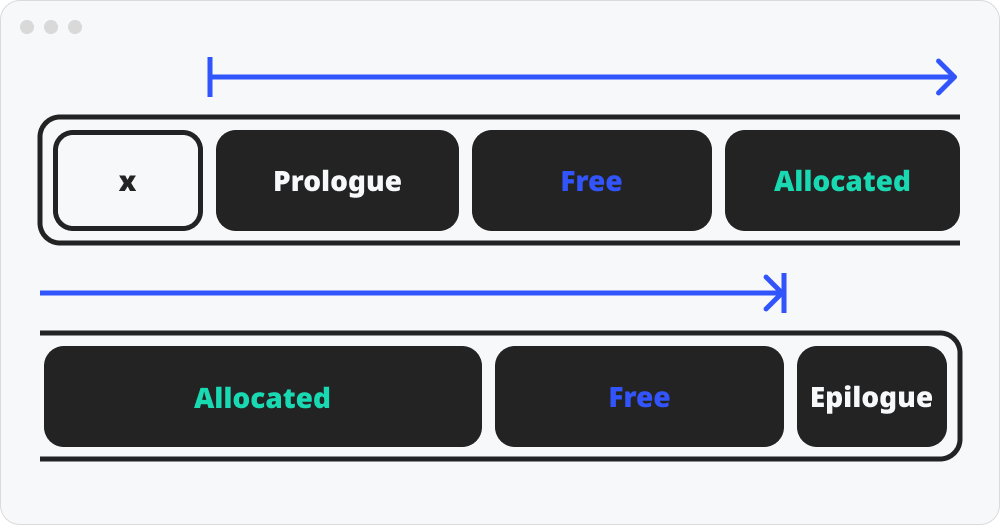
묵시적 가용 리스트를 이용하여 만든 할당기를 묵시적 메모리 할당기라고 부른다. 묵시적 메모리 할당기는 모든 힙 영역이 탐색영역이다. 탐색을 하며 헤더만으로 크기와 할당 상태를 판단한다. 구조가 단순하여 구현이 쉬운 대신 속도가 느리고 컴퓨터의 성능을 많아탄다.
묵시적 메모리 할당기를 조금 더 발전시켜 free 블록들을 명시하여 관리할 수 있다.
명시적 가용(free) 리스트
명시적 메모리 할당기는 free 블록들만 연결리스트형태로 묶은 free 리스트를 만들어 관리한다.
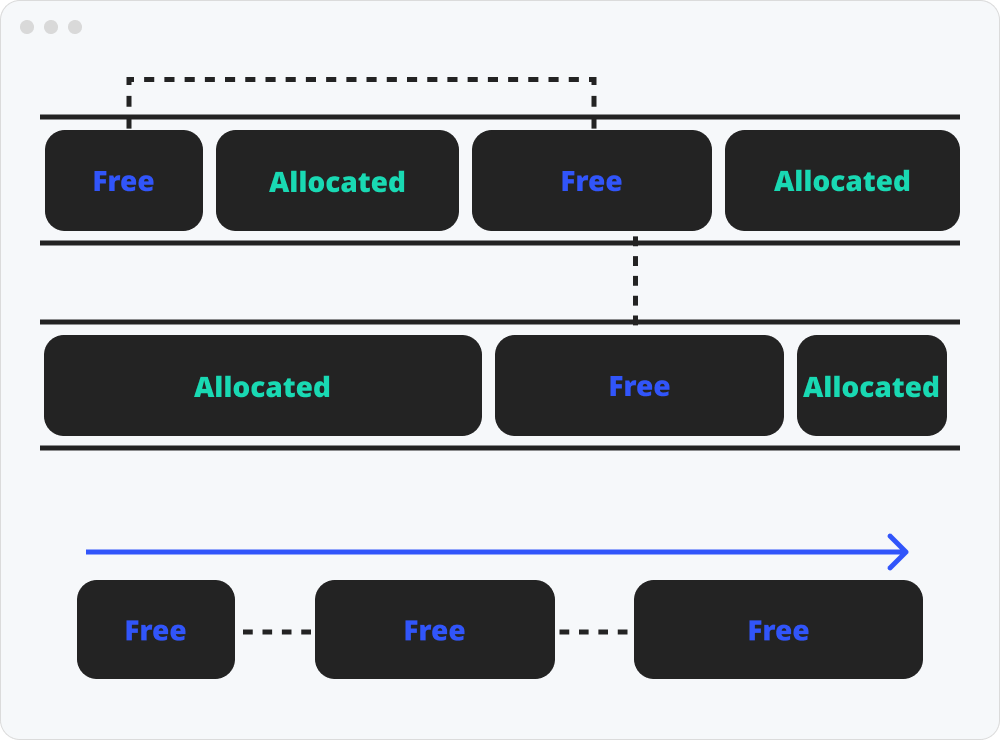
free 블록을 탐색 할 때 free 리스트만 순회하면 되기 떄문에 절대적인 탐색시간이 줄어들게 된다. 이를 구현하는 법은 명시적 메모리 할당기를 구현 할 때 더 자세히 다루겠다.
분리 가용(free) 리스트 (세그리게이티드 리스트)
명시적 메모리 할당기의 확장/고급 버전이라고 말 할 수 있다. 세그리게이티드 리스트도 변형된 형태가 다양하다. 일단은 세그리게이티드 리스트가 무엇인지 알고만 넘어가도록 하자.
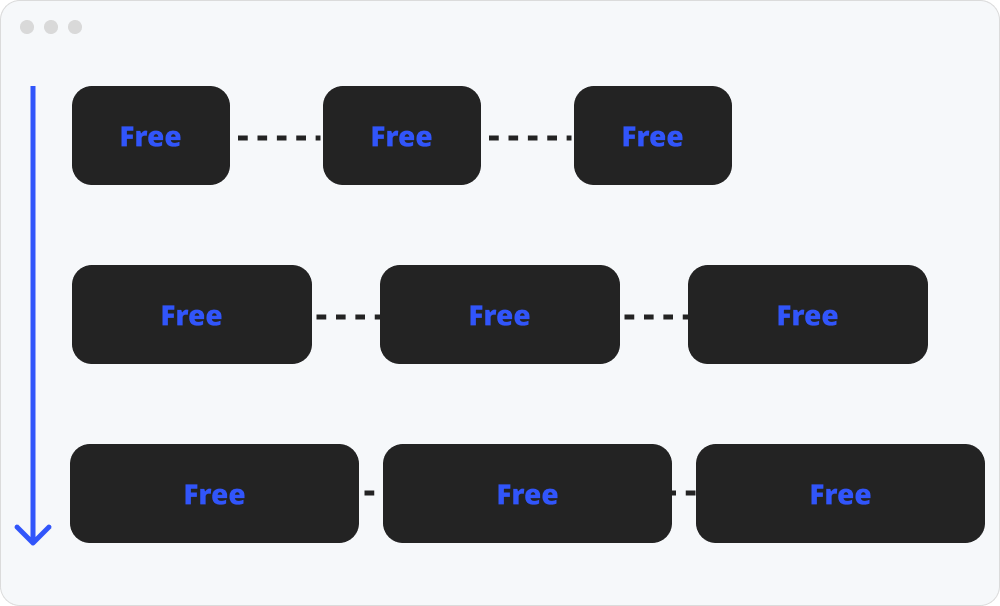
간단하게 말해서 크기별로 나눈 리스트를 따로 관리하는 구조이다. 크기 별로 존재하는 리스트에 탐색 전략을 사용해서 그 크기에 맞는 리스트에 바로 할당하는 방식이다. 리스트의 종류만 순회하면 되기에 탐색시간은 굉장히 줄어들게 되지만 구현이 복잡하고 오버헤드가 크다.
이제 드디어 구현으로 넘어갈 차례다.
묵시적 메모리 할당기 부터 구현을 해보자.